AI Technology for the World We Dream Of
Pebble Square is a fabless company dedicated to making the AI world of our dreams a reality. Using PIM (Processing-In-Memory) technology inspired by the human brain, we develop energy-efficient AI solutions that deliver top performance
-
Low Power
Consumption -

Private
(Not use cloud) -

Fast
(Instant inferencing) -

Low Cost
Powering AI Innovation with Optimized AI Chips
We specialize in AI chip design, IP licensing, AI algorithm development, and AI solution development. We create custom chips tailored to customer needs, delivering optimized AI technology for various applications
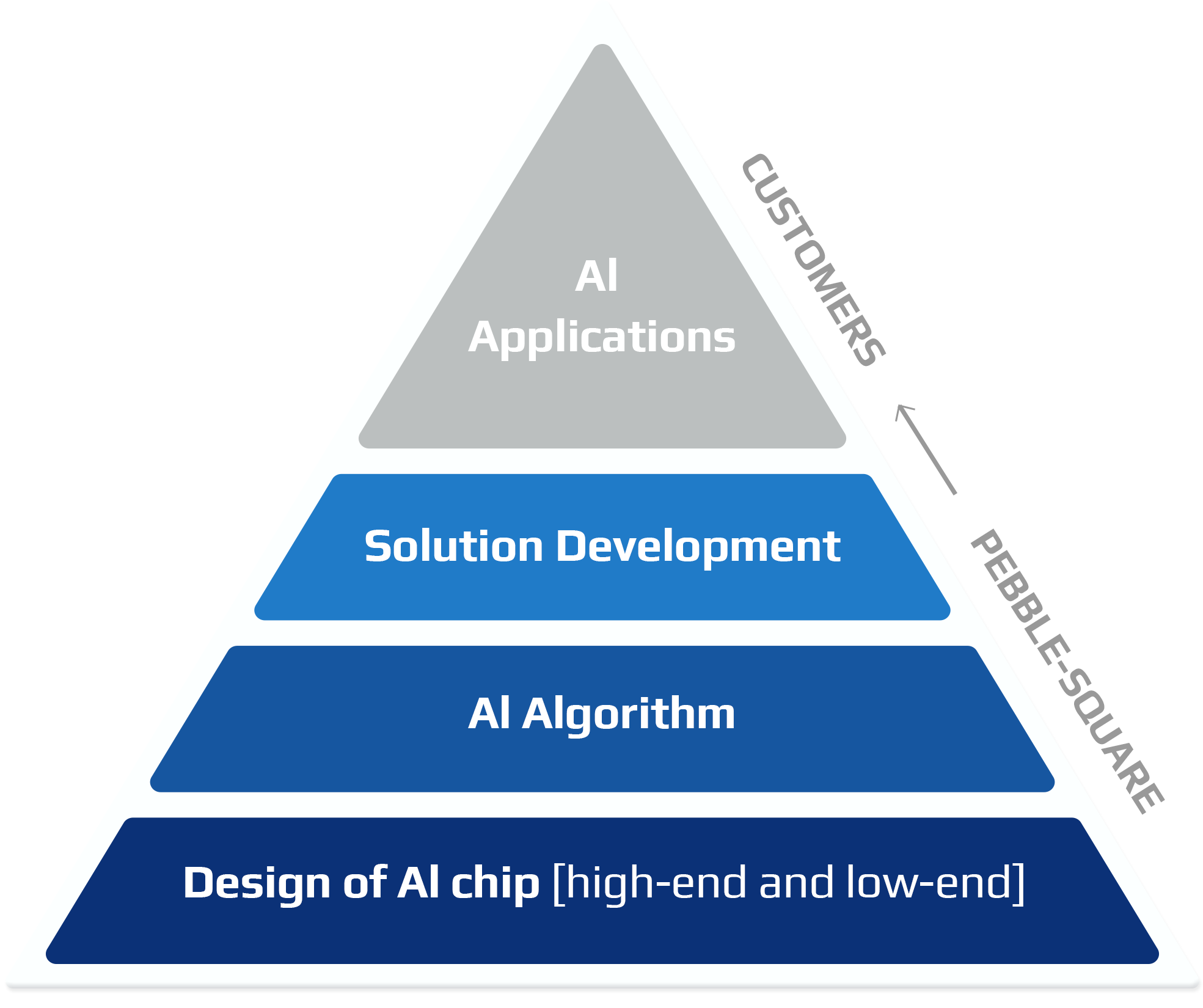
Powered by Analog PIM Technology,
Pebble Square will drive growth across industries, from smart homes and IoT devices to data centers
-
2021

Smart Home/IoT
-
2022

Image/Vision
-
2025
Auto Pilot
-
2026

Data Center